Từ Markowitz đến HERC: Tối ưu danh mục đầu tư hiện đại trên LightInvest
"Diversification is the only free lunch in investing." — Harry Markowitz, Nobel Prize 1990
Trong hơn 70 năm kể từ khi Harry Markowitz công bố lý thuyết Mean-Variance Optimization (MVO) năm 1952, ngành tài chính đã chứng kiến một cuộc cách mạng trong cách chúng ta nghĩ về phân bổ danh mục. Nhưng MVO có một bí mật mà ít sách giáo khoa nào nhắc đến: nó gần như không hoạt động trong thực tế.
Bài viết này sẽ đưa bạn qua hành trình từ Markowitz → HRP → HERC — và cách LightInvest triển khai các thuật toán này chạy ngay trên trình duyệt bằng Rust/WebAssembly.
Phần 1: Tại sao Markowitz thất bại trong thực tế?
1.1 Bài toán Mean-Variance Optimization
Markowitz (1952) đặt ra bài toán tối ưu:
Trong đó:
là vector trọng số danh mục là ma trận hiệp phương sai (covariance matrix) của lợi nhuận tài sản là vector lợi nhuận kỳ vọng là mức lợi nhuận mục tiêu
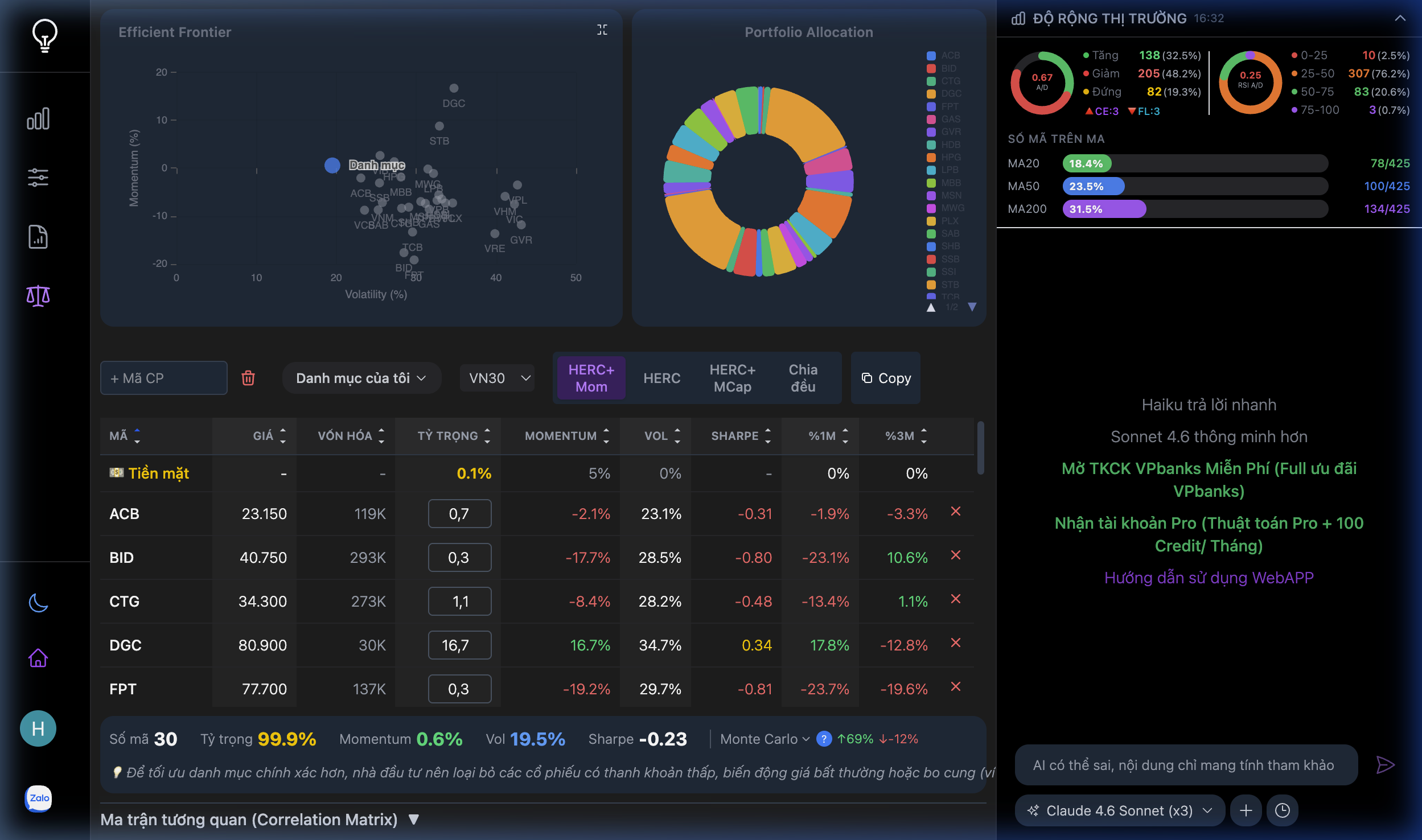
Giải bài toán này cho ta đường biên hiệu quả (Efficient Frontier) — tập hợp các danh mục tối ưu tại mỗi mức rủi ro.
1.2 "Estimation-Error Maximizer"
Vấn đề nằm ở chỗ: MVO đòi hỏi hai đầu vào mà chúng ta không thể ước lượng chính xác:
Lợi nhuận kỳ vọng (
): Gần như không thể dự đoán. Sai lệch nhỏ trong → thay đổi lớn trong trọng số tối ưu. Ma trận hiệp phương sai (
): Với tài sản, cần ước lượng tham số. Với VN100 (100 mã), đó là 5,050 tham số! Sai số tích lũy khiến kết quả mất ổn định.
"Mean-Variance Optimization is, in practice, an estimation-error maximizer." — Michaud, R. (1989). The Markowitz Optimization Enigma. Financial Analysts Journal.
1.3 "Lời nguyền Markowitz" (Markowitz's Curse)
López de Prado (2016) chỉ ra một nghịch lý: đa dạng hóa càng nhiều → kết quả càng kém ổn định. Lý do: khi thêm tài sản, ma trận
| Vấn đề | Hệ quả thực tế |
|---|---|
| Nhạy với | Thay đổi 0.1% return → danh mục xoay 180° |
| Tương quan thay đổi theo regime (bull/bear) | |
| Đòi hỏi short selling | Thị trường Việt Nam không cho phép bán khống |
| Tập trung vào 2-3 mã | Trái ngược với mục tiêu đa dạng hóa |
Phần 2: HRP — Cuộc cách mạng phân cấp
2.1 Ý tưởng đột phá của López de Prado
Năm 2016, Marcos López de Prado — người sau đó được trao giải "Quant of the Year" bởi Journal of Portfolio Management — công bố bài báo:
López de Prado, M. (2016). Building Diversified Portfolios that Outperform Out-of-Sample. Journal of Portfolio Management, 42(4), 59-69.
Ý tưởng cốt lõi: thay vì nghịch đảo ma trận
2.2 Ba bước của HRP
Bước 1: Hierarchical Clustering (Phân cụm phân cấp)
Chuyển ma trận tương quan thành khoảng cách:
Rồi áp dụng hierarchical agglomerative clustering để xây dựng dendrogram — cây phân cấp thể hiện mối quan hệ "gần/xa" giữa các tài sản.
Bước 2: Quasi-Diagonalization (Sắp xếp lại ma trận)
Sắp xếp lại các tài sản theo thứ tự lá của dendrogram, sao cho các tài sản tương quan cao nằm cạnh nhau. Ma trận
Bước 3: Recursive Bisection (Phân chia đệ quy)
Chia đệ quy danh mục thành hai nửa theo cây dendrogram. Tại mỗi nút, phân bổ vốn tỷ lệ nghịch với phương sai (variance) của mỗi nửa:
→ Nửa nào ít biến động hơn → nhận nhiều vốn hơn. Không cần nghịch đảo
2.3 Tại sao HRP vượt trội?
| Tiêu chí | MVO | HRP |
|---|---|---|
| Cần | ✅ Bắt buộc | ❌ Không cần |
| Cần nghịch đảo | ✅ Bắt buộc | ❌ Không cần |
| Ổn định out-of-sample? | ❌ Kém | ✅ Tốt hơn |
| Cho phép > assets hơn samples? | ❌ | ✅ Hoạt động bình thường |
| Kết quả trực giác? | ❌ Thường vô lý | ✅ Hợp lý |
Phần 3: HERC — Bước tiến tiếp theo
3.1 Hạn chế của HRP
HRP gốc sử dụng naive bisection — chia danh sách tài sản tại điểm giữa, bất kể cấu trúc cụm thực tế. Điều này có thể tách rời hai tài sản vốn thuộc cùng một cụm tự nhiên.
3.2 Cải tiến của Raffinot
Thomas Raffinot (2018) đề xuất HERC trong bài báo:
Raffinot, T. (2018). The Hierarchical Equal Risk Contribution Portfolio. SSRN Working Paper.
Hai cải tiến quan trọng:
Cải tiến 1: Tree-based Bisection
Thay vì chia tại midpoint, HERC chia theo nút cha/con trái/phải của dendrogram. Đảm bảo mỗi lần chia đều tôn trọng cấu trúc cụm tự nhiên.
Cải tiến 2: Linh hoạt thước đo rủi ro
MVO chỉ dùng variance. HERC cho phép sử dụng:
- Standard Deviation (mặc định trên LightInvest)
- Expected Shortfall (CVaR) — đo đuôi trái phân phối
- Conditional Drawdown at Risk (CDaR) — max drawdown kỳ vọng
3.3 Thuật toán chi tiết trên LightInvest
LightInvest triển khai HERC bằng Rust, biên dịch sang WebAssembly, chạy trực tiếp trên trình duyệt. Cụ thể:
Ward Linkage (Lance-Williams Formula)
Thay vì single-linkage (dễ bị "chaining" — tạo chuỗi dài mất cân bằng), LightInvest sử dụng Ward linkage — phương pháp gộp cụm sao cho tổng phương sai nội cụm tăng ít nhất:
Đây là công thức Lance-Williams — cho phép cập nhật khoảng cách
Tại sao Ward? Với danh mục lớn (VN100), Ward tạo cụm cân bằng kích thước → phân bổ trọng số đều hơn. Single-linkage tạo cụm "dây chuyền", dồn 80% trọng số vào 5-10 mã.
Recursive Bisection theo cây
[Root: 100%]
/ \
[Bank: 60%] [Tech+BĐS: 40%]
/ \ / \
[Big Bank] [Small] [Tech] [BĐS]
VCB,BID,CTG ACB FPT,VNG VHM,NVLTại mỗi nút, trọng số phân bổ theo nghịch đảo rủi ro cụm:
Phần 4: Biến thể HERC trên LightInvest
LightInvest cung cấp 4 chiến lược dựa trên nền HERC:
4.1 HERC+ Momentum (Mặc định)
Kết hợp HERC base với Sharpe ratio tilting — ưu tiên mã có momentum tốt hơn:
- Tính Sharpe cho từng mã:
- Return sử dụng EMA 20 ngày (nhạy hơn SMA)
- Risk-free rate = 5% (lãi suất VN)
- Volatility annualized bằng
- Z-score tilting:
Hệ số 0.5 được calibrate cẩn thận:
- Ràng buộc:
- Sharpe < 0 → giới hạn tại
(trọng số trung bình) - Max weight cap: 10-50% tùy số mã
- Iterative convergence: lặp đến khi tổng = 100%
- Sharpe < 0 → giới hạn tại
4.2 HERC (Pure Risk Parity)
HERC thuần túy không tilt — phân bổ rủi ro đều giữa các cụm. Phù hợp khi thị trường sideways, không có momentum rõ ràng.
4.3 HERC+ Market Cap
Overlay vốn hóa thị trường lên HERC base:
Sử dụng log MCap (không phải MCap thô) vì phân phối vốn hóa rất lệch phải — VCB 400K tỷ vs DGC 30K tỷ. Log transform giúp Z-score phản ánh đúng tầm quan trọng tương đối.
4.4 Chia đều (Equal Weight)
Baseline đơn giản:
Phần 5: Monte Carlo Simulation — "Tương lai" có thể đi đâu?
5.1 Geometric Brownian Motion (GBM)
LightInvest mô phỏng giá tài sản bằng GBM với Itô's Lemma drift adjustment:
Trong đó:
: drift (EMA return annualized) : volatility annualized : biến ngẫu nhiên chuẩn : hiệu chỉnh Itô — đảm bảo
Tại sao cần
? Đây là hệ quả của bất đẳng thức Jensen: khi là biến ngẫu nhiên. Nếu bỏ qua thành phần này, mô phỏng sẽ thiên lệch lên (upward bias), đánh giá quá lạc quan về danh mục.
5.2 Mô phỏng đa tài sản có tương quan
Các cổ phiếu không biến động độc lập — VCB tăng thì BID thường cũng tăng (tương quan cao). LightInvest sử dụng Cholesky decomposition để tạo biến ngẫu nhiên có tương quan:
Trong đó
5.3 Kết quả Monte Carlo
Chạy 10,000 kịch bản (paths), LightInvest cho bạn biết:
- P5 (Percentile 5%): Kịch bản xấu → "Nếu xui, mất tối đa bao nhiêu?"
- P95 (Percentile 95%): Kịch bản tốt → "Nếu thuận lợi, lãi tối đa bao nhiêu?"
- Median: Kịch bản trung bình
⚠️ Monte Carlo dựa trên biến động quá khứ. Nó KHÔNG dự đoán Black Swan — chỉ cho biết "nếu thị trường biến động tương tự quá khứ thì danh mục có thể dao động trong khoảng nào."
Phần 6: Correlation Matrix — Đa dạng hóa thực sự
Ma trận tương quan trên LightInvest giúp phát hiện:
| Tương quan | Ý nghĩa | Ví dụ (VN) |
|---|---|---|
| > 0.7 | Rất cao — giữ cả 2 = rủi ro tập trung | VCB-BID, HPG-HSG |
| 0.3 – 0.7 | Trung bình — đa dạng hóa một phần | FPT-VCB |
| < 0.3 | Thấp — đa dạng hóa tốt | FPT-VHM |
| < 0 | Âm — hedge tự nhiên | Hiếm gặp trên TTCK VN |
Phần 7: Tại sao chạy trên WebAssembly?
LightInvest biên dịch toàn bộ engine tối ưu từ Rust → WebAssembly (WASM), chạy trực tiếp trên trình duyệt:
| Tiêu chí | Server-side (Python) | WASM (Rust) |
|---|---|---|
| Tốc độ | 500ms – 2s | < 50ms |
| Bảo mật | Data gửi lên server | 100% local, data không đi đâu |
| Scalability | Server phải scale | Mỗi user tự tính trên máy |
| Offline | Không hoạt động | Hoạt động sau khi cache |
Rust + WASM = near-native performance. Ward linkage clustering cho VN100 (100 mã × 252 ngày data) hoàn thành trong ~10ms trên máy trung bình.
Tổng kết: Vì sao HERC > MVO?
1952: Markowitz MVO
↓ (vấn đề: estimation error, $\Sigma^{-1}$ không ổn định)
2016: López de Prado → HRP
↓ (cải tiến: không cần $\mu$, không cần $\Sigma^{-1}$)
2018: Raffinot → HERC
↓ (cải tiến: tree-based bisection, flexible risk measure)
2026: LightInvest → HERC+Mom/MCap trên WASM
↓ (thực chiến: Sharpe tilting, max-weight cap, Cholesky Monte Carlo)Tài liệu tham khảo
- Markowitz, H. (1952). Portfolio Selection. The Journal of Finance, 7(1), 77-91.
- Michaud, R. (1989). The Markowitz Optimization Enigma: Is "Optimized" Optimal? Financial Analysts Journal, 45(1), 31-42.
- López de Prado, M. (2016). Building Diversified Portfolios that Outperform Out-of-Sample. Journal of Portfolio Management, 42(4), 59-69.
- Raffinot, T. (2018). The Hierarchical Equal Risk Contribution Portfolio. SSRN Working Paper.
- DeMiguel, V., Garlappi, L., & Uppal, R. (2009). Optimal Versus Naive Diversification: How Inefficient is the 1/N Portfolio Strategy? Review of Financial Studies, 22(5), 1915-1953.
- Ward, J.H. (1963). Hierarchical Grouping to Optimize an Objective Function. Journal of the American Statistical Association, 58(301), 236-244.
👉 Trải nghiệm ngay: lightinvest.vn/portfolio-management
📩 Nâng cấp Pro: Facebook LightInvest